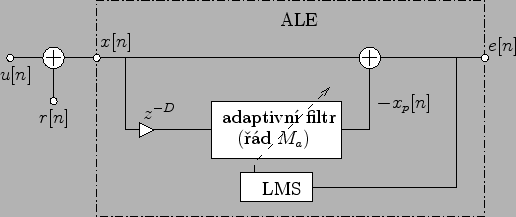
Struktura ALE (Adaptive Line Enhancer) je Obr. 5.1
Jedná se vlastně o LMS prediktor. Oproti Obr. 3.2 je uvedená
struktura trochu obecnější.
Předně umožňuje volit zpoždění ![]() ve větvi s adaptivním filtrem
(u Obr. 3.2 je toto zpoždění omezeno pouze na jeden vzorek).
Dále struktura Obr. 3.2
byla uvedena pro fixní řád adaptivního filtru.
Tento rozdíl však není tak podstatný, neboť odvození rovnic bylo
provedeno pro obecný řád.
ve větvi s adaptivním filtrem
(u Obr. 3.2 je toto zpoždění omezeno pouze na jeden vzorek).
Dále struktura Obr. 3.2
byla uvedena pro fixní řád adaptivního filtru.
Tento rozdíl však není tak podstatný, neboť odvození rovnic bylo
provedeno pro obecný řád.
Jelikož jsem v minulých cvičeních používal označení ![]() pro
řád celé struktury prediktoru, učiním tak i nyní.
Řád adaptivního filtru označím
pro
řád celé struktury prediktoru, učiním tak i nyní.
Řád adaptivního filtru označím ![]() .
Platí tedy
.
Platí tedy
V tomto cvičení se pomocí ALE budeme snažit potlačit harmonické rušení (rušení nemusí být zrovna harmonické, důležité je aby i vzdálenější vzorky rušení byly silně korelovány).
Nicméně úloha se dá různě modifikovat.
Můžeme otočit úlohu užitečného signálu a rušení.
Například budeme chtít získat harmonický signál (může se jednat o nějakou
modulaci). V tomto případě je pro nás výstupem predikce ![]() .
Nebo můžeme chtít určit frekvenci harmonického signálu
(to jsme zkoušeli na 3. cvičení).
.
Nebo můžeme chtít určit frekvenci harmonického signálu
(to jsme zkoušeli na 3. cvičení).
Označíme vektory
![\begin{displaymath}\begin{gathered}\mathbf{x}^T[n-D] = [ x[n-D], \ldots ,x[n-M] ...
...\mathbf{w}^T[n] = [ w_1[n], \ldots ,w_{M+1}[n] ] \end{gathered}\end{displaymath}](img296.png) |
(5.1) |
Cvičení 5.0:
Uvádím zde skript pro generování vstupního signálu:
N = 500; % uzitecny signal u = zeros(N,1); % nulovy % ruseni n = 1:N; Wr = pi/4; r = sqrt(2)*sin(Wr*n'); % efektivni hodnota 1 % vstupni signal x = u + r;Skript implementující ALE napište sami, viz. Obr. 5.1 a rovnice (5.2), (5.3). Nevíte-li si rady vzpomeňte si (podívejte se) na 3. cvičení, kde jsem uváděl skript pro prediktor (odlišnost je pouze v možnosti nastavit jiná zpoždění pomocí
figure(1)
subplot(4,2,1); % vyneseni modulovych spekter pri
% zachovani meritek os
W = linspace(0,2*pi,N);
plot(W/pi,abs(fft(x)),'b-');
xlabel('W/pi')
ylabel('|X|')
osy = axis;
subplot(4,2,3);
plot(W/pi,abs(fft(e)),'r-');
xlabel('W/pi')
ylabel('|E|')
axis(osy);
subplot(2,2,3); % vyneseni modulovych frekvencnich charakteristik
% (v ustalenem stavu) |H(exp(j*W))| (celeho ALE)
% a |H_a(exp(j*W))| (adaptivniho filtru)
WN =100;
W = linspace(0,2*pi,WN);
B = [1; zeros(D-1,1); w(:,N)];
A = [1; zeros(M,1) ];
H = freqz(B,A,W);
plot(W/pi,abs(H),'b-');
hold on
B_a = [ w(:,N) ];
A_a = [ 1; zeros(M_a,1) ];
H_a = freqz(B_a,A_a,W);
plot(W/pi,abs(H_a),'r-');
plot(W/pi,ones(WN,1),'g-');
hold off
xlabel('W/pi')
ylabel('|H| (modre), |H_a| (cervene)')
Výsledky:
![\includegraphics[width=10cm]{ada5/obrmat/fig1.ps}](img302.png)
|
![\includegraphics[width=10cm]{ada5/obrmat/fig2.ps}](img303.png)
|
Cvičení 5.1: Zpoždění ![]() a řád
a řád ![]() volte jako v předchozím cvičení.
Užitečný signál
volte jako v předchozím cvičení.
Užitečný signál ![]() nyní modelujte jako bílý gausovský proces s
nulovou střední hodnotou. Varianci užitečného signálu
volte podle řádu adaptivního filtru:
nyní modelujte jako bílý gausovský proces s
nulovou střední hodnotou. Varianci užitečného signálu
volte podle řádu adaptivního filtru:
![]() pro
řád
pro
řád ![]() a
a
![]() pro řád
pro řád ![]() (uvidíte, že u vyššího
řádu si můžete dovolit vyšší rozptyly
(uvidíte, že u vyššího
řádu si můžete dovolit vyšší rozptyly
![]() ).
).
Vyneste výsledky a porovnejte jako v cvičení 1 (všimněte si rozmístění
nul a pokuste se ho vysvětlit).
Vypočtěte porovnejte (pro obě volby ![]() )
dosažené SNRE (Signal to Noise Ratio Enhancement).
Dále si vyneste predikci
)
dosažené SNRE (Signal to Noise Ratio Enhancement).
Dále si vyneste predikci ![]() (výstup při obrácení úlohy
užitečného a rušivého signálu).
(výstup při obrácení úlohy
užitečného a rušivého signálu).
Pro výpočet SNRE uvádím skript. Je hodně zjednodušený například se zde započítává i přechodový děj na začátku, dále případné zesílení nebo zkreslení vstupního signálu se započítává do výkonu šumu (na druhou stranu i tyto věci nám mohou vadit a přesnější výpočet SNRE by nám je utajil)
Pu1 = sum(u.^2)/N; % výkon uzitecneho sig. na vstupu Pn1 = sum((x-u).^2)/N; % výkon ruseni na vstupu Pu2 = sum(u.^2)/N; % výkon uzitecneho sig. na vystupu Pn2 = sum((e-u).^2)/N; % výkon ruseni na vystupu SNR1 = 10*log(Pu1/Pn1); SNR2 = 10*log(Pu2/Pn2); SNRE = SNR2-SNR1; % kdyz nechcete vysledky lovit v promptu Matlabu % muzete si je vepsat do titulku nejakeho obrazku napriklad tito zpusobem: title(['SNR1 = ' num2str(SNR1) ', SNR2 = ' num2str(SNR2) ', SNRE = ' num2str(SNRE)]);Výsledky:
![\includegraphics[width=10cm]{ada5/obrmat/fig3.ps}](img306.png)
|
![\includegraphics[width=10cm]{ada5/obrmat/fig4.ps}](img307.png)
|
![\includegraphics[width=10cm]{ada5/obrmat/fig5.ps}](img308.png)
|
Poznámka: Tím, že adaptivní filtr propustí harmonické rušení
(tak aby se na chybovém výstupu ![]() vykompenzovalo) umožní minimalizaci
rozptylu na chybovém výstupu
(
vykompenzovalo) umožní minimalizaci
rozptylu na chybovém výstupu
(
![]() ). Kompenzace je zde možná, protože harmonické rušení
se dá velice dobře predikovat
5.1,
neboť jeho vzorky jsou silně korelovány (víme, že na bezchybnou predikci čistého harmonického
signálu stačí prediktor 2. řádu).
). Kompenzace je zde možná, protože harmonické rušení
se dá velice dobře predikovat
5.1,
neboť jeho vzorky jsou silně korelovány (víme, že na bezchybnou predikci čistého harmonického
signálu stačí prediktor 2. řádu).
Tento způsob však nefunguje pro bílý šum ![]() , neboť jeho korelace
mezi různými vzorky je vždy nulová.
Bílý šum se proto nedá vůbec predikovat (nejlepší predikce
je 0 - jakákoli netriviální lineární kombinace minulých vzorků dává
horší (větší)
, neboť jeho korelace
mezi různými vzorky je vždy nulová.
Bílý šum se proto nedá vůbec predikovat (nejlepší predikce
je 0 - jakákoli netriviální lineární kombinace minulých vzorků dává
horší (větší)
![]() ). Adaptivní filtr se tedy snaží
). Adaptivní filtr se tedy snaží
![]() co nejvíce potlačit (docílit nulové predikce).
co nejvíce potlačit (docílit nulové predikce).
Pravdivost těchto výroků se dá velice dobře ilustrovat na vynesených frekvenčních charakteristikách. Vidíme, že adaptivní filtr v ustálení pro vyšší řád propouští takřka pouze harmonické rušení (se zesílením 1), viz. frekvenční charakteristika adaptivního filtru na Obr. 5.5 a predikce Obr. 5.6.
Cvičení 5.2: Stáhněte si
řečový signál
a použijte ho jako užitečný signál ![]() .
Řád adaptivního filtru volte
.
Řád adaptivního filtru volte ![]() .
.
Zpoždění ![]() volte
volte
Vyneste si autokorelační funkci pro řečový signál ![]() .
Jaká volba
.
Jaká volba ![]() je optimální? Ověřte optimální volbu
je optimální? Ověřte optimální volbu ![]() výpočtem
SNRE.
výpočtem
SNRE.
Uvádím zde skript pro vynesení spektrogramů pro ![]() ,
,![]() a
a ![]() ,
který zachovává přiřazení barev.
,
který zachovává přiřazení barev.
[U,F,T] = specgram(u);
Ul = 20*log(abs(U));
[X,F,T] = specgram(x);
Xl = 20*log(abs(X));
[E,F,T] = specgram(e);
El = 20*log(abs(E));
T = 2*T; % napraveni casove osy u specgram
maxl = max(max([Ul;Xl;El])); % trochu náročné, ale krátké
minl = min(min([Ul;Xl;El]));
Ul = (Ul-minl)/(maxl-minl);
Xl = (Xl-minl)/(maxl-minl);
El = (El-minl)/(maxl-minl);
subplot(2,2,1);
imagesc(T,F,Ul);
caxis([0,1]);
axis('xy');
xlabel('n');
ylabel('|U| [dB]');
subplot(2,2,2);
imagesc(T,F,Xl);
caxis([0,1]);
axis('xy');
xlabel('n');
ylabel('|X| [dB]');
subplot(2,2,3);
imagesc(T,F,El);
caxis([0,1]);
axis('xy');
xlabel('n');
ylabel('|E| [dB]');
![\includegraphics[width=10cm]{ada5/obrmat/fig10.ps}](img309.png)
|
![\includegraphics[width=10cm]{ada5/obrmat/fig11.ps}](img310.png)
|
Poznámka: Všimněte si, že pro ![]() je řečový signál na výstupu
je řečový signál na výstupu ![]() výrazně potlačen (oproti vstupu
výrazně potlačen (oproti vstupu ![]() ), viz. moduly spekter, dosažené
SNRE a spektrogramy na Obr. 5.7.
Je to tím, že blízké vzorky řeči jsou významně korelovány (narozdíl od
bílého šumu v předchozím cvičení).
Vzpomeňte si, jak jste na 2. cvičení modelovali řeč jako AR proces
10. řádu.
), viz. moduly spekter, dosažené
SNRE a spektrogramy na Obr. 5.7.
Je to tím, že blízké vzorky řeči jsou významně korelovány (narozdíl od
bílého šumu v předchozím cvičení).
Vzpomeňte si, jak jste na 2. cvičení modelovali řeč jako AR proces
10. řádu.
Pro ![]() můžete pozorovat výrazné zlepšení, viz. moduly spekter,
dosažené SNRE a spektrogramy na Obr. 5.8.
Důvod je ten, že korelace mezi příspěvkem řeči na vstupu
můžete pozorovat výrazné zlepšení, viz. moduly spekter,
dosažené SNRE a spektrogramy na Obr. 5.8.
Důvod je ten, že korelace mezi příspěvkem řeči na vstupu ![]() a na zpožděních adaptivního filtru
a na zpožděních adaptivního filtru
![]() již není
tak vysoká. Řeč se tedy pro
již není
tak vysoká. Řeč se tedy pro ![]() hůře predikuje než pro
hůře predikuje než pro ![]() a
proto se na chybovém výstupu hůře kompenzuje.
a
proto se na chybovém výstupu hůře kompenzuje.
Čím méně jsou příspěvky užitečného signálu ![]() korelovány s příspěvky
užitečného signálu na zpožděních adaptivního filtru tím lepších
výsledků dosáhneme. Tento fakt je ilustrován na porovnání průběhů
autokorelační funkce řečového signálu
korelovány s příspěvky
užitečného signálu na zpožděních adaptivního filtru tím lepších
výsledků dosáhneme. Tento fakt je ilustrován na porovnání průběhů
autokorelační funkce řečového signálu ![]() :
: ![]() ,
,
![]() a závislosti dosaženého SNRE na zpoždění
a závislosti dosaženého SNRE na zpoždění ![]() uvedeném na
Obr. 5.9.
uvedeném na
Obr. 5.9.
![\includegraphics[width=10cm]{ada5/obrmat/fig12.ps}](img314.png)
|