Náhodný proces ![]() je AR (autoregressní) proces řádu
je AR (autoregressní) proces řádu ![]() , jestliže platí
, jestliže platí
Nyní předpokládejme, že máme k dispozici realizaci procesu
![]() a známe řád AR procesu. Naším úkolem bude odhadnout jeho koeficienty
případně
a známe řád AR procesu. Naším úkolem bude odhadnout jeho koeficienty
případně ![]() .
.
Zde stručně uvedeme odhad metodou nejmenších čtverců, který byl
uveden (podrobně) na přednášce
2.2.
Nejprve nebudu předpokládat nic o stacionaritě případně ergodicitě
![]() , tedy
, tedy ![]() může být nyní nestacionární (AR koeficienty
případně variance budícího procesu
může být nyní nestacionární (AR koeficienty
případně variance budícího procesu ![]() se mohou měnit v čase).
se mohou měnit v čase).
Rovnice (2.1) vyjádříme budící proces
Nyní již samotné odvození.
Označme vektor koeficientů a vektor zpožděných vzorků signálu ![]()
![\begin{displaymath}
\begin{gathered}
\mathbf{a}^T = [ a_1, \ldots, a_M ], \\
\mathbf{x}^T[n-1] = [ x[n-1], \ldots, x[n-M] ].
\end{gathered}\end{displaymath}](img167.png)
![$\displaystyle \nabla_{\mathbf{a}} (\mathrm{E}[e^2[n]])
=
\frac{\partial \mathrm...
...2[n]]}{\partial \mathbf{a}}
=
2 \mathbf{r}_p + 2 \mathbf{R}_{xx} \mathbf{a}
.
$](img180.png)
Nyní již víme jak z momentů ![]() AR koeficienty odhadnout otázkou
je jak odhadnout momenty
AR koeficienty odhadnout otázkou
je jak odhadnout momenty ![]() .
To jsme ale probíraly na minulém cvičení. Například víte-li, že signál
lze považovat za stacionární a ergodický na úsecích nějaké
fixní délky, můžete použít blokový odhad atd..
.
To jsme ale probíraly na minulém cvičení. Například víte-li, že signál
lze považovat za stacionární a ergodický na úsecích nějaké
fixní délky, můžete použít blokový odhad atd..
V následujících úlohách se stručně podíváme na problematiku komprese řečového signálu. Řečový signál lze zjednodušeně popsat jako AR proces jehož parametry se v čase mění viz. Obr. 2.2. Přenosu řečového signálu naznačuje Obr. 2.4
Řečový signál putuje od mluvčího přes mikrofon A/D převod atd. na vstup analyzujícího filtru. Zpracování probíhá obvykle po blocích. V rámci každého bloku se odhadnou AR koeficienty. AR koeficienty spolu s informacemi o chybě predikce (např.Stáhněte si nějaký řečový signál například tento a načtěte si jej do MATLABu
x = load("rec.asc");
Cvičení 2.1: Vaším úkolem je blokově odhadnout AR koeficienty (2.9) a varianci
budícího procesu (2.10) pro řečový signál ![]() .
Předpokládejte fixní řád AR modelu řeči
.
Předpokládejte fixní řád AR modelu řeči ![]() a dále
stacionaritu a ergodicitu řeči na úsecích délky
a dále
stacionaritu a ergodicitu řeči na úsecích délky ![]() (použijte bloky
délky
(použijte bloky
délky ![]() ).
).
Poznámka: K odhadu autokorelační matice použijte vnějšího součinu jako v (2.8)
x = x(:); % udela z x sloupcovy vektor
N = length(x);
M = 10; % rad
L = 256; % delka bloku
B = floor(N/L); % pocet bloku
y = zeros(N,1); e = zeros(N,1); u = zeros(N,1);
for b = 1:B; %B %4
% kodovani
x_blok = x( (b-1)*L+1:L*b );
range = 1+M:L;
X = zeros(L-M,M+1);
for k = 1:M+1
X(:,k) = x_blok(range-k+1);
end;
Rxx_ = X'*X/(L-M); % spocteme autokorelacni matici Rxx_ o rozmeru M+1
Rxx = Rxx_(1:M,1:M); % vybereme autokorelacni matici Rxx o rozmeru M
rp = Rxx_(2:M+1,1); % a vektor rp
a = -inv(Rxx)*rp;
e_vykon = Rxx(1,1) + rp'*a; % vykon chyby predikce
end
Cvičení 2.2: Pro jeden blok2.5Vyneste predikci ![]() spolu s původním signálem
spolu s původním signálem ![]() a
chybou predikce
a
chybou predikce ![]() .
.
an_A = [1; zeros(M,1)]; % koeficienty analyzujícího filtru
an_B = [1;a];
xp_blok = -filter([0;a],an_A,x_blok); % predikce
e_blok = x_blok - xp_blok; % chyba pridikce
% e_blok = filter(an_B,an_A,x_blok);
Cvičení 2.3: Nyní se pokuste řeč syntetizovat.
V každém bloku z odhadnutých AR koeficientů vytvořte syntetizující
filtr. Tento filtr vypadá jako na Obr. 2.2 je
inverzní k analyzujícímu.
Jako jeho buzení ![]() použijte:
použijte:
Pro každý případ buzení porovnejte výsledek syntézy ![]() s
řečovým signálem
s
řečovým signálem ![]() .
.
Pro každý případ buzení si pro jeden blok
vyneste: původní signál ![]() , výsledek syntézy
, výsledek syntézy ![]() ,
chybu predikce
,
chybu predikce ![]() a buzení syntetizujícího filtru
a buzení syntetizujícího filtru ![]() .
.
Nevynášejte pouze časové průběhy, ale rovněž výkonová spektra v decibelech
(lépe odhady PSD), rovněž si vyneste kvadrát modulu frekvenční
charakteristiky syntetizujícího filtru v decibelech, abyste ho
mohli porovnat s výkonovým spektrem ![]() , případně
, případně ![]() .
.
Při porovnávání výsledku syntézy ![]() s
původním řečovým signálem
s
původním řečovým signálem ![]() je dobré si signály
poslechnout (např. sound(y)), a vynést.
Vyneste si rovněž spektrogramy obou signálů
(např. specgram(y)2.6),
jde z nich vyčíst více než z časových průběhů.
je dobré si signály
poslechnout (např. sound(y)), a vynést.
Vyneste si rovněž spektrogramy obou signálů
(např. specgram(y)2.6),
jde z nich vyčíst více než z časových průběhů.
Skript pro syntézu ![]() zde neuvádím. Zmíním se pouze o vynášení
výkonových spekter.
zde neuvádím. Zmíním se pouze o vynášení
výkonových spekter.
figure
minp = 1e-3;
W = linspace(0,2*pi,100); % frekvence
% vykonove spektrum v [dB]
plot((0:L-1)/L*2, 10*log10(abs(fft(x_blok)).^2/L+minp), 'b' );
hold on
% modul |H|^2 vynasobeny vykonem chyby predikce v [dB]
plot(W/pi,10*log10(abs(freqz(sy_B*sqrt(e_vykon),sy_A,W)).^2) , 'r');
hold off
title('|X|^2 (modre), |H|^2*sigma')
ylabel('[dB]')
xlabel('norm. frekv. (W/pi)')
![\includegraphics[width=10cm]{ada2/obrmat/fig6.ps}](img193.png)
|
![\includegraphics[width=10cm]{ada2/obrmat/fig7.ps}](img194.png)
|
![\includegraphics[width=10cm]{ada2/obrmat/fig8.ps}](img195.png)
|
![$\displaystyle x[n] = -\sum_{m=1}^{M} a_m x[n-m] + v[n],$](img151.png)
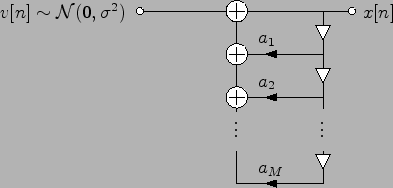
![$\displaystyle v[n] = x[n] + \sum_{m=1}^{M} a_m x[n-m].$](img156.png)
![$\displaystyle e[n] = x[n] + \sum_{m=1}^{M} a_m' x[n-m],$](img160.png)
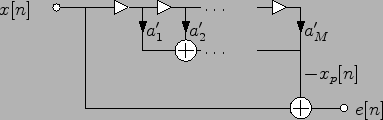
![$\displaystyle x_p[n] = - \sum_{m=1}^{M} a_m' x[n-m].$](img162.png)
![\begin{equation*}\begin{aligned}\mathrm{E}[e^2[n]] &= \mathrm{E}[x^2[n] + 2 x[n]...
...{r}_p + \mathbf{a}^T \mathbf{R}_{xx} \mathbf{a}, \\ \end{aligned}\end{equation*}](img170.png)
![\begin{equation*}\begin{aligned}\mathrm{E}[e^2[n]]_{min} &= \mathrm{E}[x^2[n]] +...
...athrm{E}[x^2[n]] + \mathbf{r}_p^T \mathbf{a}_{opt}. \end{aligned}\end{equation*}](img184.png)

![\includegraphics[width=10cm]{ada2/obrmat/fig4.ps}](img189.png)
![\includegraphics[width=10cm]{ada2/obrmat/fig2.ps}](img192.png)