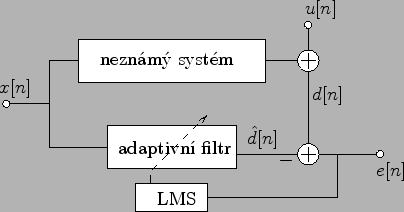
V úloze identifikace je naším cílem určit neznámý systém (jeho impulsovou odezvu), máme-li k dispozici jeho vstup a výstup. To můžeme učinit paralelním připojením adaptivního filtru, jak je naznačeno na Obr. 4.2.
LMS se snaží nastavovat váhy adaptivního filtru tak, aby byl
výkon na chybovém výstupu minimální. Je zřejmé, že výkon chyby ![]() bude minimální právě tehdy, když impulsové odezvy obou systémů budou
shodné. Impulsovou odezvu neznámého systému pak určíme z vah
adaptivního filtru. Úloha může být dále komplikována přítomností
aditivního šumu
bude minimální právě tehdy, když impulsové odezvy obou systémů budou
shodné. Impulsovou odezvu neznámého systému pak určíme z vah
adaptivního filtru. Úloha může být dále komplikována přítomností
aditivního šumu ![]() . Správná funkce struktury Obr. 4.2 je pak
podmíněna nekorelovaností
. Správná funkce struktury Obr. 4.2 je pak
podmíněna nekorelovaností ![]() a
a ![]() .
.
Cvičení 4.0: Vygenerujte si signál ![]() jako bílý gausovský šum s nulovou
střední hodnotou a rozptylem
jako bílý gausovský šum s nulovou
střední hodnotou a rozptylem ![]() .
Vygenerujte si signál
.
Vygenerujte si signál ![]() jako bílý gausovský šum s nulovou
střední hodnotou a rozptylem
jako bílý gausovský šum s nulovou
střední hodnotou a rozptylem ![]() .
Délky obou posloupností volte
.
Délky obou posloupností volte ![]() vzorků.
Neznámý systém budeme reprezentovat vektory koeficientů čitatele a jmenovatele
přenosové funkce plant_B a plant_A
4.1.
Nastavte plant_B = [ 0.5; -1.5 ] a
plant_A = [ 1; 0 ] (FIR řádu 1).
vzorků.
Neznámý systém budeme reprezentovat vektory koeficientů čitatele a jmenovatele
přenosové funkce plant_B a plant_A
4.1.
Nastavte plant_B = [ 0.5; -1.5 ] a
plant_A = [ 1; 0 ] (FIR řádu 1).
N = 500; % pocet vzorku M = 1; % rad Adaptivniho filtru % kyticka plant_b1 = 0.5; plant_b2 = -1.5; plant_B = [plant_b1;plant_b2]; % FIR, rad 1 plant_A = [1;0]; u_sigma = 0.3; % rozptyl^0.5 aditivniho ruseni x = randn(N,1); % bily sum u = u_sigma*randn(N,1); % aditivniho ruseni
Cvičení 4.1: Napište m-file implementující strukturu Obr. 4.2. Pro
libovolný řád adaptivního filtru ![]() .
Konvergenční konstantu LMS algoritmu
.
Konvergenční konstantu LMS algoritmu ![]() volte
mu = 0.1/((M+1)*rozptyl_x[n]).
Vyneste si průběh vah na čase a ověřte, že se blíží správným
hodnotám.
volte
mu = 0.1/((M+1)*rozptyl_x[n]).
Vyneste si průběh vah na čase a ověřte, že se blíží správným
hodnotám.
d = filter(plant_B,plant_A,x) + u;
Výsledky:
Cvičení 4.2: Jako buzení ![]() použijte
místo bílého šumu AR proces druhého řádu (barevné buzení).
Póly all-pole filtru v AR modelu volte komplexně sdružené
použijte
místo bílého šumu AR proces druhého řádu (barevné buzení).
Póly all-pole filtru v AR modelu volte komplexně sdružené
![]() .
Normujte rozptyl AR procesu na jedna.
.
Normujte rozptyl AR procesu na jedna.
Vyneste si opět průběhy vah a porovnejte je s původními průběhy pro buzení bílým šumem. Sledujte rozdíly v rychlosti konvergence, pokuste se objasnit příčiny pozorovaného chování LMS.
Vygenerovat ![]() vzorků AR procesu, máme-li zadané póly by měl umět již každý
(dělali jsme to třeba již na 1. cvičení, a v druhém jsme AR procesy
důkladně popsali). Časově problematická je ale část normování rozptylu
(integrace), proto zde uvádím celý m-file.
vzorků AR procesu, máme-li zadané póly by měl umět již každý
(dělali jsme to třeba již na 1. cvičení, a v druhém jsme AR procesy
důkladně popsali). Časově problematická je ale část normování rozptylu
(integrace), proto zde uvádím celý m-file.
x_pol_r = 0.95; % poloha polu barevne buzeni x_pol_W = pi/6; a = x_pol_r*exp(j*x_pol_W); x_vykon = 2 / (abs(a)^2-1) * real( a/(a-conj(a))/(a^2-1) ); x_A = [1, -2*x_pol_r*cos(x_pol_W), x_pol_r^2]; x_B = [1, 0, 0]/sqrt(x_vykon); x = filter(x_B,x_A,randn(N,1));
Výsledky:
Poznámka: Proč je konvergence u barevného buzení tak špatná?
Volíme-li ![]() příliš malé, zajistíme tím konvergenci (stabilitu)
adaptivního
filtru, ale filtr se nebude stíhat dostatečně rychle adaptovat na
změny v signálu (zde změny identifikovaného systému).
Z tohoto hlediska se snažíme volit
příliš malé, zajistíme tím konvergenci (stabilitu)
adaptivního
filtru, ale filtr se nebude stíhat dostatečně rychle adaptovat na
změny v signálu (zde změny identifikovaného systému).
Z tohoto hlediska se snažíme volit ![]() co největší.
To ale na druhou stranu může vést k divergenci filtru.
Z přednášky víte, že horní mez pro volbu
co největší.
To ale na druhou stranu může vést k divergenci filtru.
Z přednášky víte, že horní mez pro volbu ![]() (aby LMS bylo ještě
stabilní) je nepřímo úměrná výkonu (rozptylu) buzení
(čím větší výkon buzení, tím menší
(aby LMS bylo ještě
stabilní) je nepřímo úměrná výkonu (rozptylu) buzení
(čím větší výkon buzení, tím menší ![]() musíme volit).
musíme volit).
Je-li výkon (PSD) buzení soustředěn pouze v úzkém pásmu
(Jako u našeho barevného buzení), a ![]() nastavíme na onu horní mez, bude konvergence v tomto pásmu rychlá.
Ale z hlediska ostatních pásem bude konvergence pomalá, neboť zde
je filtr vybuzen minimálně a volba
nastavíme na onu horní mez, bude konvergence v tomto pásmu rychlá.
Ale z hlediska ostatních pásem bude konvergence pomalá, neboť zde
je filtr vybuzen minimálně a volba ![]() je z hlediska těchto pásem
příliš konzervativní (nízká).
Při buzení bílým šumem je konvergence
optimální (ve všech pásmech stejně rychlá).
Tedy ačkoli pro oba případy filtr konverguje v průměru stejně
rychle (obě buzení mají stejný rozptyl),
u barevného buzení se musí čekat i na ty nejpomalejší pásma, proto zde
konvergence trvá déle.
je z hlediska těchto pásem
příliš konzervativní (nízká).
Při buzení bílým šumem je konvergence
optimální (ve všech pásmech stejně rychlá).
Tedy ačkoli pro oba případy filtr konverguje v průměru stejně
rychle (obě buzení mají stejný rozptyl),
u barevného buzení se musí čekat i na ty nejpomalejší pásma, proto zde
konvergence trvá déle.
Toto vysvětlení je dosti vágní a sedí hlavně pro filtry vyšších řádů. u filtrů nižších řádů bychom už museli přesněji vymezit co je to ono frekvenční pásmo. Tuto úvahu se snaží ilustrovat následující cvičení.
Cvičení 4.3: Vygenerujte ![]() realizací
realizací ![]() (doslova musíte vygenerovat
(doslova musíte vygenerovat ![]() realizaci
realizaci ![]() a
a ![]() a z nich
a z nich ![]() -krát vygenerovat
-krát vygenerovat ![]() a
a ![]() )
)
Vyneste průběh
![]() (MSE - Mean Square Error)
na
(MSE - Mean Square Error)
na ![]() pro oba typy buzení
(operátor
pro oba typy buzení
(operátor
![]() uplatněte tak
jak je psáno, tedy přes realizace nikoli přes čas - nyní žádnou stacionaritu
a ergodicitu nepředpokládáme).
uplatněte tak
jak je psáno, tedy přes realizace nikoli přes čas - nyní žádnou stacionaritu
a ergodicitu nepředpokládáme).
Až průběhy
![]() vynesete zjistíte, že se velmi podobají
exponenciálám. Z tohoto důvodu je lepší vynášet v decibelech,
exponenciály přejdou na přímky a vše je hned lépe vidět.
vynesete zjistíte, že se velmi podobají
exponenciálám. Z tohoto důvodu je lepší vynášet v decibelech,
exponenciály přejdou na přímky a vše je hned lépe vidět.
Uvádím m-file pro generování více realizací:
R = 200; % pocet realizaci (pouze pro vypocet E[.]) X = zeros(N,R); U = zeros(N,R); D = zeros(N,R); for r = 1:R genx; % Vas skript pro generovani x[n], u[n], a d[n] X(:,r) = x; U(:,r) = u; D(:,r) = d; end; % vypocet R realizaci e[n] E = zeros(N,R); for r=1:R x = X(:,r); d = D(:,r); ident; % Vas skript pro generovani e[n] z x[n] a d[n] E(:,r) = e; end;a skript na výpočet MSE:
mse = sum(E.^2')'/R;Výsledky:
![\includegraphics[width=10cm]{ada4/obrmat/fig3.ps}](img274.png)
|
Další precizování důvodů rozdílné konvergence v závislosti na buzení je uvedeno v dodatku 4.3 o chybovém povrchu. Tento dodatek trochu předbíhá přednášku, kde se o chybovém povrchu dozvíte později, ale zdálo se mi, že se přece jenom na toto cvičení (alespoň zmínka) hodí tak si ho prohlédněte (je tam spousta obrázků).
Cvičení 4.4: Nyní nám bude opět stačit jediná realizace ![]() a vpřípadě buzení
se omezíme na bílý šum.
Jako neznámý systém použijte integrátor s pólem v
a vpřípadě buzení
se omezíme na bílý šum.
Jako neznámý systém použijte integrátor s pólem v ![]() .
.
Vyneste si frekvenční charakteristiku odpovídající nastavení
![]() adaptivního filtru a porovnejte ji s charakteristikou
identifikovaného systému (integrátoru).
adaptivního filtru a porovnejte ji s charakteristikou
identifikovaného systému (integrátoru).
Sledujte jak závisí shoda obou charakteristik na volbě řádu ![]() adaptivního filtru.
adaptivního filtru.
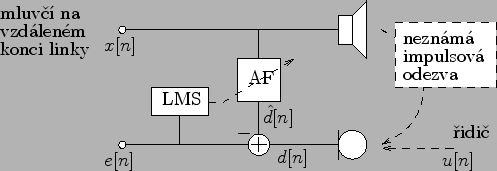
Problém je naznačen na obrázku Obr. 4.7
Jde nám o to aby ![]() obsahoval pouze hlas řidiče nikoli
mluvčího na druhém konci linky. Vidíte, že se jedná opět o úlohu
identifikace. Takže můžete použít skripty vytvořené v předchozích
cvičeních akorát zaměníte použité signály.
obsahoval pouze hlas řidiče nikoli
mluvčího na druhém konci linky. Vidíte, že se jedná opět o úlohu
identifikace. Takže můžete použít skripty vytvořené v předchozích
cvičeních akorát zaměníte použité signály.
Cvičení 4.5: Jako ![]() (mluvčí na vzdáleném konci linky) použijte
tento řečový signál.
Jako
(mluvčí na vzdáleném konci linky) použijte
tento řečový signál.
Jako ![]() (řidič) použijte
tento řečový signál.
Oba signály ořízněte na délku
(řidič) použijte
tento řečový signál.
Oba signály ořízněte na délku ![]() vzorků.
Impulsovou odezvu od reproduktoru k mikrofonu (identifikovaný systém)
volte jako zpoždění o 4 vzorky.
Řád adaptivního filtru volte
vzorků.
Impulsovou odezvu od reproduktoru k mikrofonu (identifikovaný systém)
volte jako zpoždění o 4 vzorky.
Řád adaptivního filtru volte ![]() .
Vyneste si spektrogramy signálů
.
Vyneste si spektrogramy signálů ![]() ,
, ![]() ,
, ![]() ,
, ![]() .
.
Výsledky:
![\includegraphics[width=10cm]{ada4/obrmat/fig12.ps}](img281.png)
|
![\includegraphics[width=10cm]{ada4/obrmat/fig1.ps}](img269.png)
![\includegraphics[width=10cm]{ada4/obrmat/fig2.ps}](img271.png)
![\includegraphics[width=10cm]{ada4/obrmat/fig10.ps}](img277.png)
![\includegraphics[width=10cm]{ada4/obrmat/fig11.ps}](img278.png)