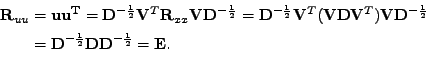Mějme nezávislé náhodné procesy
![]() ,
,
![]() (k dispozici máme pouze segment délky
(k dispozici máme pouze segment délky ![]() )
s nulovou
střední hodnotou a nenulovou variancí10.1.
)
s nulovou
střední hodnotou a nenulovou variancí10.1.
Uspořádejme procesy do vektorů
Tedy najít něco jako inverzi k
![]() (
(
![]() )
Protože máme k dispozici pouze nezávislost složek
)
Protože máme k dispozici pouze nezávislost složek
![]() nelze doufat v obnovení pořadí a měřítek jednotlivých složek jako
u inverze
10.2.
nelze doufat v obnovení pořadí a měřítek jednotlivých složek jako
u inverze
10.2.
Vektory náhodných procesů
zde nebudu již značit
![]() ,
,
![]() ,
ale zavedu značení
,
ale zavedu značení
![]() ,
podobně pro
,
podobně pro
![]() , abych lépe rozlišil vektor náhodných
procesů
, abych lépe rozlišil vektor náhodných
procesů
![]() od jeho hodnoty v čase
od jeho hodnoty v čase ![]() , kterou budu
značit i nadále
, kterou budu
značit i nadále
![]() (náhodný vektor).
(náhodný vektor).
Nyní si úkol trochu zjednoduššíme, od vektorů (délky ![]() ) náhodných procesů
) náhodných procesů
![]() ,
,
![]() přejdeme k náhodným vektorům
přejdeme k náhodným vektorům
![]() ,
,
![]() (délky
(délky ![]() ).
Náhodné vektory
).
Náhodné vektory
![]() ,
,
![]() dodefinujeme tak,
abychom realizaci
dodefinujeme tak,
abychom realizaci
![]() mohli chápat jako
mohli chápat jako ![]() realizací
realizací
![]() , a aby nezávislost složek
, a aby nezávislost složek
![]() přešla
na nezávislost složek
přešla
na nezávislost složek
![]() .
Bude to vyžadovat další omezení na
.
Bude to vyžadovat další omezení na
![]() a příjdeme tím
o část informace, kterou bychom mohli použít, ale věc se tím podstatně
zjednodušší:
a příjdeme tím
o část informace, kterou bychom mohli použít, ale věc se tím podstatně
zjednodušší:
Jednu možnost jak
![]() a
a
![]() dodefinovat nyní popíšu.
Jednu realizaci
dodefinovat nyní popíšu.
Jednu realizaci
![]() a
a
![]() vygeneruji následuji následujícím způsobem. Vygeneruji realizaci
vygeneruji následuji následujícím způsobem. Vygeneruji realizaci
![]() , pak vygeneruji časový index
, pak vygeneruji časový index ![]() z rovnoměrného
rozdělení na
z rovnoměrného
rozdělení na
![]() .
.
![]() zvolím jako hodnotu právě
vygenerované realizace
zvolím jako hodnotu právě
vygenerované realizace
![]() v čase
v čase ![]()
Postup je pak takový se od složek
![]() snažíme přejít
k původním složkám
snažíme přejít
k původním složkám
![]() , za předpokladu jejich nezávislosti
a tak odhadnout separační matici
, za předpokladu jejich nezávislosti
a tak odhadnout separační matici
![]() k mixážní matici
k mixážní matici
![]() .
Je-li
.
Je-li
![]() skutečně separační k
skutečně separační k
![]() 10.4nic nám již
nebrání jí použít na procesy
10.4nic nám již
nebrání jí použít na procesy
![]() a získat tak původní
procesy
a získat tak původní
procesy
![]() .
.
K tomu je ale nutné vědět, zda nezávislost
![]() vede na nezávislost
vede na nezávislost
![]() (je-li možné nezávislost
(je-li možné nezávislost
![]() při separaci z
při separaci z
![]() použít). Zmíněnou implikaci lze pro uvedenou konstrukci
použít). Zmíněnou implikaci lze pro uvedenou konstrukci
![]() skutečně dokázat pro
stacionární
skutečně dokázat pro
stacionární
![]() a za jistých dodatečných přijatelných předpokladů
i pro
a za jistých dodatečných přijatelných předpokladů
i pro
![]() nestacionární.
nestacionární.
Nyní se podívejme na situaci z hlediska statistik 2. řádů (korelačních
matic). Z předpokladu nezávislosti složek
![]() plyne
jejich nekorelovanost tedy korelační matice náhodného vektoru
plyne
jejich nekorelovanost tedy korelační matice náhodného vektoru
![]()
Chceme-li obnovit nezávislost musíme složky
![]() určitě
dekorelovat (z nezávislosti plyne nekorelovanost). Problém je
že dekorelací obecně nezávislost nezajistíme (opačná implikace neplatí).
Těžko tedy můžeme doufat, že pouze s pomocí statistik 2. řádů dosáhneme
separace pro jakouko-li regulární
určitě
dekorelovat (z nezávislosti plyne nekorelovanost). Problém je
že dekorelací obecně nezávislost nezajistíme (opačná implikace neplatí).
Těžko tedy můžeme doufat, že pouze s pomocí statistik 2. řádů dosáhneme
separace pro jakouko-li regulární
![]() .
.
Úlohu si tedy
trochu zjednoduššíme a omezíme se (alespoň v této části) pouze na
ortogonální mixážní matici
![]() a dálé budeme
předpokládat, že
a dálé budeme
předpokládat, že
![]() nemá násobná vlastní čísla.
nemá násobná vlastní čísla.
Z ortogonality
![]() a diagonality
a diagonality
![]() použitím lematu
7.5
plyne, že (10.6) je vlastním rozkladem
použitím lematu
7.5
plyne, že (10.6) je vlastním rozkladem
![]() .
Vypočtu tedy vlastní rozklad
.
Vypočtu tedy vlastní rozklad
![]() - určím ortogonální matici
- určím ortogonální matici
![]() a diagonální matici
a diagonální matici
![]() tak, aby
tak, aby
Sestrojíme tedy součin
![]() a ověřme zda je
a ověřme zda je
![]() skutečně separační k
skutečně separační k
![]() . Jelikož připouštíme pouze různá
vlastní čísla
. Jelikož připouštíme pouze různá
vlastní čísla
![]() (všechny mají násobnost právě jedna)
přísluší podle lemmatu 7.4 každému vlastnímu číslu
(všechny mají násobnost právě jedna)
přísluší podle lemmatu 7.4 každému vlastnímu číslu ![]() právě jeden lineárně nezávislý
vlastní vektor
právě jeden lineárně nezávislý
vlastní vektor
![]() . Jelikož jsme se omezili pouze na
. Jelikož jsme se omezili pouze na
![]() , je
, je
![]() příslušný
příslušný ![]() určen
jednoznačně až na znaménko
určen
jednoznačně až na znaménko
![]() .
Oba rozklady
.
Oba rozklady
![]() se tedy mohou lišit pouze pořadím (permutací) vlastních čísel
(na diagonálách
se tedy mohou lišit pouze pořadím (permutací) vlastních čísel
(na diagonálách
![]() a
a
![]() ) a vlastních
vektorů (v maticích
) a vlastních
vektorů (v maticích
![]() a
a
![]() ). Vlastní vektory
se navíc mohou lišit znaménkem.
Označme sloupcové vektory
). Vlastní vektory
se navíc mohou lišit znaménkem.
Označme sloupcové vektory
![]() .
Z ortogonality
.
Z ortogonality
![]() pro skalární součiny
pro skalární součiny
![]() plyne
plyne
![]() pro
pro ![]() a
a
![]() . Označme sloupce
. Označme sloupce
![]() . Z uvedeného plyne, že
se jedná pouze o permutované vektory
. Z uvedeného plyne, že
se jedná pouze o permutované vektory
![]() s případnou změnou znaménka. Skalární součiny
s případnou změnou znaménka. Skalární součiny
![]() ,
z nichž se skládá zkoumaný součin
,
z nichž se skládá zkoumaný součin
![]() ,
mají pouze následující hodnoty
,
mají pouze následující hodnoty
![]() (pro
(pro
![]() ,
,
![]() )
)
![]() (pro
(pro
![]() )
nebo
)
nebo
![]() (pro
(pro
![]() ).
Jelikož kopie
).
Jelikož kopie
![]() (včetně případné změny znaménka)
se v
(včetně případné změny znaménka)
se v
![]() vyskytuje právě jednou, je v každém řádku
vyskytuje právě jednou, je v každém řádku
![]() právě jeden nenulový prvek (
právě jeden nenulový prvek (![]() nebo
nebo ![]() ).
V každém sloupci rovněž (v uvedené úvaze obratíme
úlohu
).
V každém sloupci rovněž (v uvedené úvaze obratíme
úlohu
![]() a
a
![]() ). Matice
). Matice
![]() je tedy
podle definice 10.1
separační
k
je tedy
podle definice 10.1
separační
k
![]() a
a
K separaci použitím
![]() dojde i pro trochu obecnější
dojde i pro trochu obecnější
![]() .
Nechť
.
Nechť
![]() má tvar
má tvar
Jelikož těžko můžeme doufat v obnovení měřítek (
![]() je neznámá)
normují se většinou rozptyly výsledku na
je neznámá)
normují se většinou rozptyly výsledku na ![]() . To lze zařídit přenásobením
. To lze zařídit přenásobením
![]() (diagonální matice, která má na diagonále
odmocniny převrácených hodnot diagonálních prvků
(diagonální matice, která má na diagonále
odmocniny převrácených hodnot diagonálních prvků
![]() viz.
(10.7), tedy
viz.
(10.7), tedy
![]() )
)
V předešlém textu jsme hledání separační matice založili na
podobnosti vyjádření
![]() pomocí
pomocí
![]() a
vlastního rozkladu.
To nám dovolilo najít případy
(tvary
a
vlastního rozkladu.
To nám dovolilo najít případy
(tvary
![]() ) pro které je
) pro které je
![]() skutečně
separační maticí.
skutečně
separační maticí.
Nyní uvažujme obecnou regulární mixážní matici. Máme k dispozici předpoklad
nezávislosti složek
![]() . Složky
. Složky
![]() ,
kde
,
kde
![]() označuji separační matici musí být rovněž nezávislé.
Z (10.12) vidíme, že volba
označuji separační matici musí být rovněž nezávislé.
Z (10.12) vidíme, že volba
![]() vede na dekorelaci složek (nejsou zde potřeba žádé restrikce na tvar
vede na dekorelaci složek (nejsou zde potřeba žádé restrikce na tvar
![]() kromě regularity). To ale ještě neznamená nezávislost
složek.
Transformace
kromě regularity). To ale ještě neznamená nezávislost
složek.
Transformace
![]() tedy vždy složky
tedy vždy složky
![]() dekoreluje, ale jenom někdy (viz. výše diskutované
tvary
dekoreluje, ale jenom někdy (viz. výše diskutované
tvary
![]() (10.10)) je i rozseparuje.
(10.10)) je i rozseparuje.
![$\displaystyle \mathbf{M} = \left[\begin{array}{cc}
\cos\alpha & -\sin\alpha \\
\sin\alpha & \cos\alpha
\end{array}\right], \;\;\;\; \alpha=\frac{\pi}{3}
,
$](img740.png)
![$\displaystyle \mathbf{M} = \left[\begin{array}{cc}
1 & -2 \\
1 & -0.3
\end{array}\right]
.
$](img741.png)
Vytvořte směs
![]() , viz. (10.2).
, viz. (10.2).
Určete korelační matici
![]() vektoru
vektoru
![]() (jak bylo popsáno vzorky
(jak bylo popsáno vzorky
![]() pro jednotlivé
časy považujete za realizace náhodného vektoru
pro jednotlivé
časy považujete za realizace náhodného vektoru
![]() ).
Vypočtěte ortogonální matici
).
Vypočtěte ortogonální matici
![]() a diagonální matici
a diagonální matici
![]() vlastního rozkladu matice
vlastního rozkladu matice
![]() .
K tomu lze použít volání [V,D] = eig(Rxx).
.
K tomu lze použít volání [V,D] = eig(Rxx).
Vypočtěte ![]() realizací
realizací
![]()
Pro všechny případy A1, A2, B1, B2,
C1, C2 vyneste realizace náhodných vektorů
![]() ,
,
![]() ,
,
![]() ,
,
![]() .
Do grafu pro
.
Do grafu pro
![]() si vyneste standardní bázi a
vyneste si také jak transformuje.
Do grafů si rovněž vyneste závislost variance na směru.
Vyneste si výsledné průběhy
si vyneste standardní bázi a
vyneste si také jak transformuje.
Do grafů si rovněž vyneste závislost variance na směru.
Vyneste si výsledné průběhy
![]() .
.
Uvádím skript pro vynesení realizací náhodného vektoru
![]() , standardní báze, a variance na směru pro náhodný vektor
, standardní báze, a variance na směru pro náhodný vektor
![]() :
:
figure(1)
subplot(2,2,1)
plot(s(1,:),s(2,:),'g.'); % realizace
hold on
Bs = diag([1;1]); % standardni baze
plot([ 0 Bs(1,1) ],[ 0 Bs(2,1) ] ,'b-');
plot([ 0 Bs(1,2) ],[ 0 Bs(2,2) ] ,'b-');
% variance na smeru
wN = 50
w = [cos(linspace(0,2*pi,wN));sin(linspace(0,2*pi,wN))]; % smerove vektory
var = zeros(1,wN);
for n = 1:wN;
p = w(:,n)'*s;
m1 = sum(p)/N;
m2 = sum(p.^2)/N;
var(n) = m2 - m1^2;
end;
plot( var.*w(1,:), var.*w(2,:),'r-');
title("s");
xlabel("s_1");
ylabel("s_2");
axis('equal')
hold off
![\includegraphics[width=10cm]{ada10/obrmat/fig1.ps}](img745.png)
|
![\includegraphics[width=10cm]{ada10/obrmat/fig2.ps}](img749.png)
|
![\includegraphics[width=10cm]{ada10/obrmat/fig3.ps}](img750.png)
|
![\includegraphics[width=10cm]{ada10/obrmat/fig4.ps}](img751.png)
|
![\includegraphics[width=10cm]{ada10/obrmat/fig5.ps}](img752.png)
|
![\includegraphics[width=10cm]{ada10/obrmat/fig6.ps}](img753.png)
|
U případu s ortogonální mixážní maticí Obr. 10.1 vidíme, že se
již po alikaci
![]() podařilo obnovit původní signály
včetně měřítek viz. Obr. 10.2. Pro neortogonální
regulární k separaci již nedojde (nezávislé směry neodpovídají
standardní bázi
podařilo obnovit původní signály
včetně měřítek viz. Obr. 10.2. Pro neortogonální
regulární k separaci již nedojde (nezávislé směry neodpovídají
standardní bázi
![]() ) viz.
Obr. 10.3 a Obr. 10.4,
Obr. 10.5, Obr. 10.6.
Nicméně vidíme, že vždy dojde k vybělení (velikost variance
nezávisí na směru - červené kružnice v grafu realicací
) viz.
Obr. 10.3 a Obr. 10.4,
Obr. 10.5, Obr. 10.6.
Nicméně vidíme, že vždy dojde k vybělení (velikost variance
nezávisí na směru - červené kružnice v grafu realicací
![]() ).
Také je patrné, že k separaci již stačí pouze otočení (nezávislé směry
v grafu realicací
).
Také je patrné, že k separaci již stačí pouze otočení (nezávislé směry
v grafu realicací
![]() svírají pravý úhel).
Všiměte si že úhel tohoto otočení lze vyčíst z průběhu špičatosti
na směru, kromě případu gausovských šumů (normální rozdělení má
nulovou špičatost).
Pouze s použitím nezávislosti zde nelze původní nezávislé směry
obnovit, neboť
jakékoli dva ortogonální směry jsou zde nezávislé (jedná se o
centrálně symetrické normální rozdělení).
svírají pravý úhel).
Všiměte si že úhel tohoto otočení lze vyčíst z průběhu špičatosti
na směru, kromě případu gausovských šumů (normální rozdělení má
nulovou špičatost).
Pouze s použitím nezávislosti zde nelze původní nezávislé směry
obnovit, neboť
jakékoli dva ortogonální směry jsou zde nezávislé (jedná se o
centrálně symetrické normální rozdělení).
![$\displaystyle p(\mathbf{s}) = \sum_{n=0}^{N-1} p(n) p(\mathbf{s}\vert n) = \sum_{n=0}^{N-1} \frac{1}{N} p(\mathbf{s}[n]) .$](img691.png)